강의 링크
https://www.youtube.com/watch?v=dJYGatp4SvA&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r
강의 슬라이드
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture01.pdf
1강이라 그런지 Computer Vision의 역사에 대해서 교양 강의 느낌으로 가볍게 훑는데
안 볼 사람은 안 봐도 될거 같다. 솔직히 나도 나중가면 까먹을 듯 ㅋㅋㅋㅋㅋㅋ
=========================================================================
Computer Vision이란 시각 데이터를 처리, 인식, 및 추론하는 인공 시스템을 구축하는 것이라고 할 수 있다.

시간이 지날 수록 visual data의 양이 기하 급수적으로 증가하고 있으며,
예를 들어 유튜브의 경우 매 분당 300시간의 동영상이 올라오는 데 이런 방대한 양의 데이터를 사람이
직접 처리할 수는 없다. 그래서 오늘날 Deep Learning을 활용한 Computer Vision이 각광받는 이유이기도 하다.

여기서 Deep Learning이란, 머신러닝의 한 갈래로 사람의 뇌를 모방하여 수많은 레이어들을 활용하여 계층적으로 구성된 학습 알고리즘이라고 할 수 있다.

본 강의에서는 위의 범위에 해당되는 내용을 다룬다고 한다.

Computer Visoin은 Hubel과 Wiesel의 1959년의 연구로부터 시작되었다.
그들은 포유류의 뇌가 시각적 자극에 대해 어떻게 반응하는지를 관찰했고,
이 과정에서 simple cell이 간단한 자극에 반응을 하고, 이 simple cell들이 모여서 complex cell이 되고 복잡한 자극에
반응한다는 것을 알게 되었다.
뭔가 CNN에서 feature 추출해서 Object Detect하는게 여기서 착안한거 같기도 하다.

이어서 1963년 Larry Roberts는 raw visual data를 컴퓨터가 이해할 수 있도록 기하학적으로 처리했으며

1970년대 David Marr는 이미지의 3D로 표현하는 단계를 제시했다.

그리고 1973년과 1979년에 Object Recognition에 관한 연구도 진행되었는데 이미지를 Pictorial Structure와 Generalized Cylinder로 처리하여 물체를 인식하려고 하였다. 하지만 그 당시 열악한 컴퓨터 성능으로 인해 큰 진전은 없었다.

1980년대에 들어 지속적인 컴퓨팅 파워의 향상으로 드디어 실제 이미지를 이용한 연구가 시작되었다.
John Canny는 1986년 이미지에서 edge를 찾고 edge matching을 통하여 object recognition을 수행하는 방식을
제시했다.

1990년대에 들어 사람들은 더 복잡한 이미지를 이용하여 연구를 수행하기 시작했는데,
1997년에는 image segmentation을 이미지에 적용해보는 등의 일을 했으며

1999년에는 object의 key point를 저장해서 object의 각도가 바뀐다던가 노이즈가 있는 등의 상태가 바뀌어도 올바르게
object를 detection 할 수 있는 연구가 진행되었다.

그리고 2001년, Vioila와 Jones은 머신 러닝을 이용하여 얼굴 인식 기술을 개발했다.
그들은 Boosted Decision Tree를 사용해 얼굴을 인식했으며 여기에 사용된 기술은 얼마 지나지 않아서
카메라에 이식되었다고 한다.

Computer Vision을 위해서는 방대한 데이터가 필요하고 그래서 이를 위한 ImageNet이라는 Data Set이
2009년 완성되어 사람들에게 제공되기 시작했으며 이 데이터를 이용하여 Image Classification Challenge가 열였다.

위 그래프가 그 대회의 우승자의 정확도를 나타낸 것인데 2012년 이전에는 미미하게 개선 되다가

2012년 Deep Learning을 활용한 CNN 구조의 AlexNet의 도입으로 큰 폭의 개선이 이루어지고 이후 급격하게 발전하여
결국 사람보다도 더 정확한 결과를 보여주는 것을 볼 수 있다. 이미지 인식에 Deep Learning을 활용한 것이 AlexNet이 처음인 것은 맞지만, 이 기술은 갑자기 튀어 나온 것이 아니라 이전의 수많은 연구들이 있었기에 존재할 수 있었다.
이전까지는 Computer Vision의 역사에 관해 다루었다면 이제는 Computer Vision에서 핵심적인 역할을 하는 Deep Learning에 대해서도 다루어 볼 것이다.

Perceptron은 데이터로부터 학습할 수 있는 일종의 알고리즘으로 초기에는 위와 같이 하드웨어의 형태로 구현되었다.
이 기계는 알파벳을 인식할 수 있었으며 일종의 Linear Classifier라고 볼 수 있다. 이 기계의 발명으로 인해 사람들은 하나하나 프로그래밍 하지 않아도 기계 스스로 학습할 수 있는 메커니즘의 가능성을 알게 되었다.

1980년 Fukushima는 Hubel과 Wiesel의 Hierachy of Complex and Simple Cell에서 영감을 받아서 이에 대한 Computational model을 만들었다. 이 모델에서는 simple cell은 convolution으로 complex cell은 pooling으로
처리했는데 이는 AlexNet과 유사한 구조라고는 할 수 있다. 하지만 아쉽게도 이 모델을 어떻게 학습시킬지는 따로 제시하지는 않았다.

1986년, Rumelhart와 Hinton, Williams은 Multi layer perceptron을 학습시키는 알고리즘인 Backprop을 제안했다.
여기서 제안된 Backprop은 현대 머신러닝 알고리즘의 밑바탕이 된다.
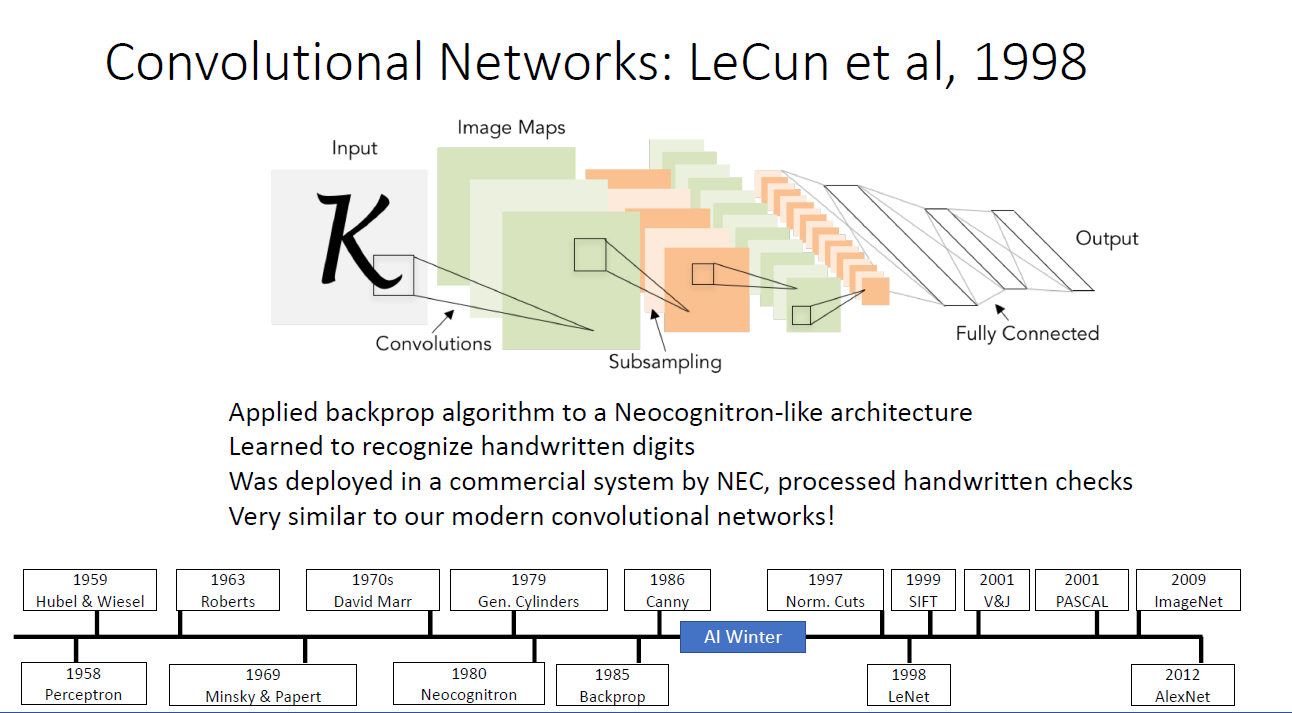
1998년, LeCun et al은 이론으로나 존재하던 Convolutional Network를 만들어냈다.
그는 Neocognitron의 아키텍처와 backprop을 결합하였는데 학문적, 상업적으로 큰 영향을 끼쳤다.
Neocognition을 참고하여 만들었기에 마찬가지로 AlexNet과 유사한 구조임을 알 수 있다.
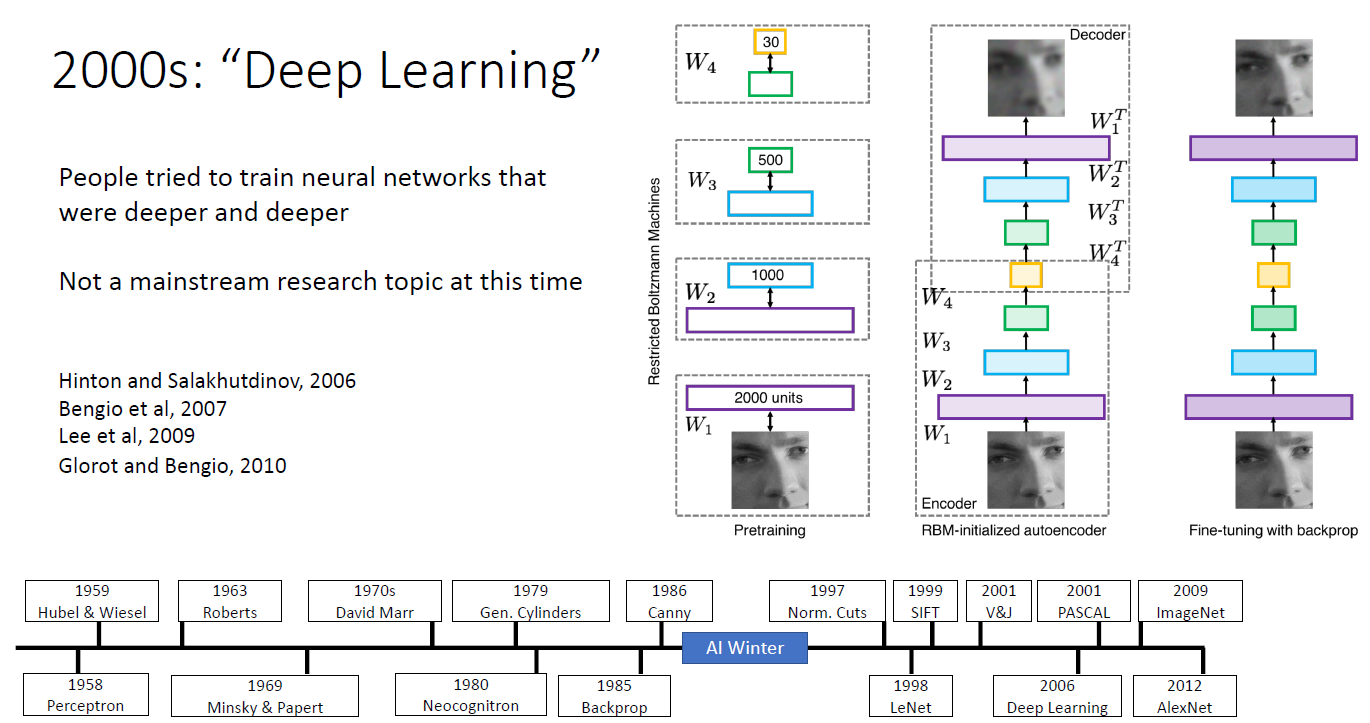
2000년대에 들어 드디어 Deep Learning을 적용시키려는 시도가 생기기 시작되었다. 하지만 여전히 머신러닝의 주류는 아니었다.

그리고 시간이 흘러 2012년, AlexNet의 등장과 함께 Deep Learning에 대한 관심과 수요가 급격하게 증가하였으며,
CNN (Convolution Neural Network) 다른말로 ConvNet을 활용한 이미지 처리 기술은 사회 전반적인 부분에 적용되기 시작하였다.

위와 같은 2012년의 Deep Learning 붐은 이전에까지 다루었던 Algorithm과 Data 영역에서의 발전말고도
Computation 영역에서도 큰 발전이 있었기에 가능했다.

위의 그래프를 보면 GPU 영역에서의 성능이 지수함수적으로 증가함을 알 수 있다.
수많은 연산이 수행되어야하는 Deep Learning 특성과 과거, 컴퓨팅 파워의 한계로 연구 또한 한계를 맞은 것을 생각하면 Deep Learning의 발전에는 Computation 영역의 발전이 큰 지분을 차지한다고 할 수 있다.
강의는 여기서 끝나고 수업의 첫 강의 답게 이 다음은 평가 항목이나 강사 소개 등의 강의 OT가 진행된다.

강의는 위와 같이 진행되고 과제가 6개 정도 나가며
다음 강의 듣고 나면 첫번째 과제가 주어진다는데 흠... 벌써???
'Deep Learning for Computer Vision' 카테고리의 다른 글
| EECS 498-007 / 598-005 Lecture 4 : Optimization (0) | 2021.01.11 |
|---|---|
| EECS 498-007 / 598-005 Lecture 3 : Linear Classifier (2) | 2021.01.07 |
| EECS 498-007 / 598-005 Assignment #1 (0) | 2020.12.31 |
| EECS 498-007 / 598-005 Lecture 2 : Image Classification (0) | 2020.12.30 |
| EECS 498-007 / 598-005 시작! (0) | 2020.12.26 |


