강의 링크
https://www.youtube.com/watch?v=g6InpdhUblE&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=5
강의 슬라이드
https://web.eecs.umich.edu/~justincj/slides/eecs498/498_FA2019_lecture05.pdf

Linear Classifier는 간단한만큼, Geometric Viewpoint나 Visual Viewpoint에서 확인할 수 있듯이, 한계가 많다.

이러한 한계는 Feature Transform으로 어느 정도 극복이 가능하지만, 현실적으로 고차원의 데이터를 적절히
Feature Transform 하기 위해서는 고려해야 할 것이 한 둘이 아니다. 그래도 Feature Transform을 잘 이용하기만 하면
괜찮은 성능을 보여주어 Computer Vision 분야에서 많이 쓰이고 있다.

대표적인 예시가 Color Histogram인데, Color Histogram에서는 이미지의 구조 등은 무시하고 단순히 이미지에서 색상별 빈도를 가지고 히스토그램을 만들어서 이미지를 분석한다. 이 방식을 사용하면 기존의 이미지 속 객체의 각도나, 위치 등이 달라지는 문제 등에 대처할 수 있다.

Color Histogram 말고도 Histogram of Oriented Gradients (HoG) 또한 Feature Transform의 분야 중 하나인데,
이 방식에서는 이미지에서 local edge만 남기고, 이것들만을 이용해서 이미지를 분석한다.
HoG는 2000년대 중후반까지 Object Detection에서 많이 사용되었다.

앞서 언급된 Color Histogram과, Histogram of Oriented Gradients 모두 어떤 feature를 어떻게 추출할 것이냐 등,
구현에 있어 많은 노력이 필요하였다. 그래서 구현에 있어 더 간단한 Bag of Words라는 Data-Driven 방식이 새롭게
제안되었는데, 이 방식은 2단계로 나뉜다.
일단 먼저 학습 데이터의 각 이미지 별로 무작위로 patch들을 추출한 후에 각 patch들을 클러스터링해서
각 patch들의 군집으로 이루어진 'visual word'로 구성된 'codebook'이란 것을 만든다.
그리고 학습이 끝난 후, 입력으로 이미지를 받으면 이미지에서 각 'visual word'가 얼마나 존재하는지, 히스토그램으로
표현한 후에 이를 통해 이미지를 분석한다.

이미지에서 Color Histogram이나 Histogram of Oriented Gradients 등의 방식으로 여러 개의 feature vector를 만든 후,
이를 하나의 vector로 통합하여 사용하는 방식도 있다. 이 방식은 2000년대 후반부터 2010년대 초반까지 많이 쓰였는데,

2011년의 ImageNet challenge의 우승자는 이 방식을 채택하여 우승할 수 있었다.

지금까지 언급한 방식들 모두, 사람의 거의 모든 과정에 개입하여야 했다. 하지만 AlexNet부터 활발히 사용된
Neural Network부터는 feature representation조차 스스로 학습해나가는 end to end 방식의 모델이 가능해졌다.

Neural Network, 즉 신경망 모델은 Linear Classifier를 적층해서 구성하며, 대부분의 신경망 모델을 표현할 때,
bias 항은 관습적으로 생략한다고 한다.

신경망 모델에서는 이전 레이어의 element가 다음 레이어의 element에 영향을 미치는 것을 알 수 있는데,
신경망 모델의 이러한 특성 때문에 Fully Connected Neural Network 혹은 Multi Layer Perceptron(MLP)라고도 부르기도 한다.

Linear Classifier는 각 카테고리당 1개의 템플릿만 만들지만



2-Layer Neural Network에서는 카테고리당 1개의 템플릿만을 만드는 것이 아니고, 첫 번째 레이어에서
각각의 Weigth 마다 템플릿을 만들어 내고, 두번째 레이어에서는 이전에 만든 템플릿들을 재조합해서 class score를
만들어 낸다.
이처럼 1개의 템플릿이 아닌 여러 개의 템플릿의 조합으로 class를 표현한다고 해서 이 방식을
'Distributed Representation'이라고 부르기도 한다.
신경망 모델에서는 여러 개의 템플릿을 만들기에 중복된 정보를 가진 템플릿을 만들 수도 있지만,
Network Pruning과 같은 기술들로 어느 정도는 해소할 수 있다고 한다.

신경망 모델에서 Depth는 layer의 수를 뜻하며, Width는 각 layer의 크기를 말한다.
그리고 s를 만들어 낼때 사용되는 max는 activation function인 'relu'를 나타내는데,

신경망 모델에서 activation function을 적용하지 않으면 수학적으로는 Linear Classifier와 다를 바가 없어지게 된다.
activation function이 없는 신경망 모델을 deep linear network라고 부르는데, 그래도 optimization 측면에서는
알아볼 가치가 있다고 한다.

relu 말고도 다양한 activation function이 있는데, 위의 'sigmoid'는 2000년대 중반까지 많이 쓰였으며
현재는 대부분 relu를 기본으로 사용하고 있는 추세이다.
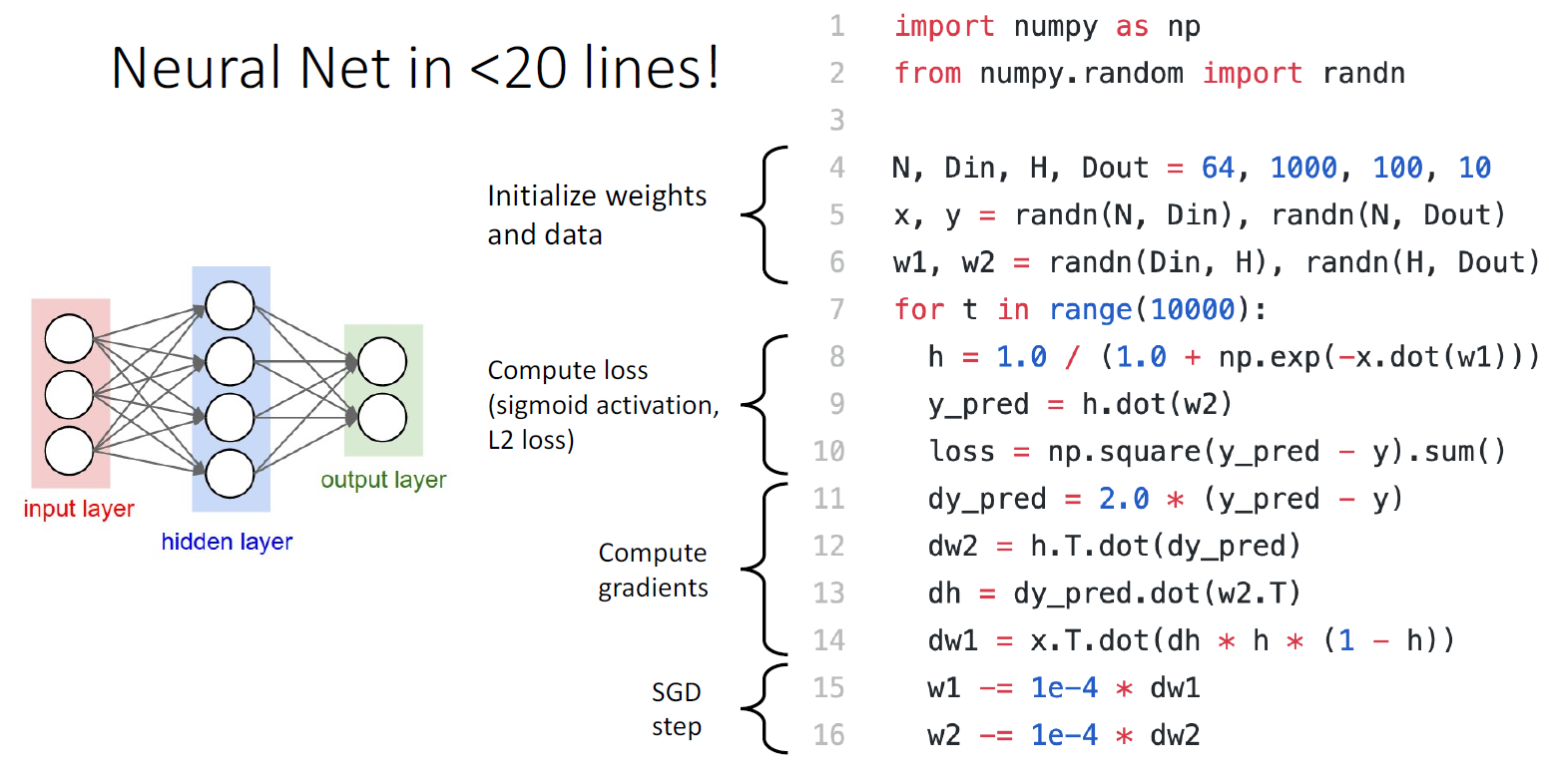
신경망 모델을 구현할 때에는 end to end 방식으로 구현이 가능하기에 위 코드처럼 정말로 손쉽게 구현할 수 있다.

강의에서 몇 분동안 사람의 뇌에 있는 뉴런에 대해 생물학적으로 간단히 설명하는데,

세부적으로 들어가면 다르지만 신경망 모델과 뇌의 뉴런이 동작 자체만은 비슷하다는 사실만 알면 될 듯하다.


신경망 모델은 뇌에서의 뉴런의 복잡한 연결을 단순화하여 구현한 것인데, 단순한 구조 말고도 랜덤 하게 연결한 구조나, 복잡하게 연결된 구조도 작동하기는 한다고 한다.

위 슬라이드처럼 실제 뉴런과 Neural Net은 많은 차이가 존재하기에 'Neural' 이라는 단어에 연연할 필요는 없다고 한다.

Neural Network가 Linear Classifier에 비해 우월한 성능을 나타내는 것은 Distributed Representation 말고도
Space Warping 때문인데,

기존 Feature Transform 방식은 Linear Transform이라서 데이터를 완전히 분리할 수가 없었다.

하지만 Neural Net에서 Relu와 같은 activation Function을 사용하면

데이터가 Linear Classifier가 적절히 분리할 수 있게 변환되어 Non Linear하게 배치된 데이터도 적절히 분리할 수 있게 된다.

히든 레이어에서 더 많은 유닛을 사용하는 것은 데이터에 더 많은 line을 그어 구분하는 것과 동일한데
그렇기 때문에 더 적은 유닛을 사용하면 과적합 문제를 완화할 수 있게 된다.

그렇다고 해서 유닛의 수로 이 문제를 처리하기 보다는 regularizer로 처리해야 한다.

1개의 히든 레이어를 가진 신경망 모델로 어떤 함수든 근사하여 표현이 가능한데 이걸
Universal Approximation이라고 한다.

2-layer relu network의 출력 Y는 위와 같은 shift 되고 scale 된 relu의 합이라고 할 수 있다.


임의로 shift되고 scale된 4개의 relu를 모아서 위와 같은 bump function을 만들 수 있는데, 이 bump function을
이용하면 어떤 함수든 근사할 수 있으며, 그래서 2-layer neural network가 Universal Approximation가
가능하다고 하는 것이다.

하지만 Neural Network로 Universal Approximzation이 가능하다고 해서 Neural Network가 Bump Function 자체를
학습하는 것이라고 볼 수는 없다. 또한 Universal Approximation은 Neural Network가 어떤 함수든지 표현이 가능하다는
사실만 알려줄 뿐, SGD를 사용했을 때도 어떤 함수든지 표현이 가능하다는 사실을 알려주는 것도 아니고,
학습에 데이터가 얼마나 필요하다는 사실도 알려주지 않는다.
그래서 단순히 Universal Approximation이 가능하다고 해서 Neural Network가 최고의 모델이라는 주장을 해서는
안된다. 낮은 성능을 보여주는 KNN 또한 Universal Approximation이 가능하다.
지금까지는 Neural Network의 장점에 대해서 말했다면 이제는 Optimization에 관해서 다룰 것이다.

어떤 함수에서 임의의 두 점을 잇는 선분을 그었을 때, 항상 두 점 사의에 위치한 점들이 모두 선분 아래에 위치한다면
그 함수를 Convex Function이라고 한다.

이 사실이 성립되지 않는 코사인 함수는 Convex Function이 아니라고 할 수 있다.

고차원 공간에서의 Convex Function은 bowl shape을 그리는 함수를 지칭하며, Convex Function은 기울기를 따라 내려간다면 간단히 global minimum에 도달할 수 있다. 그래서 Convex Function에서는 초기화에 따른 영향도 덜하다.

Linear 모델에서는 항상 convex 함수가 Global Minimum에 도달하는 것이 이론적으로 보장되어 있지만,
Neural Network에서는 그러한 이론적 뒷받침이 존재하지 않는다.
그래서 일부 경우에는 Linear 모델이 더 선호되기도 한다.

Neural Network에서는 Convex Function임을 확인하고 싶을 때, 고차원의 loss에서 Weight Vector W에서 1개의 원소에
해당하는 slice를 떠서 확인하는데, slice가 Convex를 이룰 때도 있지만,



아닐 때도 있다.

그래서 대부분의 Neural Network에서는 nonconvex를 이루는 데이터에 대해서도 optimization 방안이 필요하다.
이러한 optimization에 대해서는 global minimum으로 수렴하는 어떠한 근거는 없지만
그래도 실전에서는 괜찮게 작동한다고 한다.




'Deep Learning for Computer Vision' 카테고리의 다른 글
| EECS 498-007 / 598-005 Assignment #2-2 (1) | 2021.01.16 |
|---|---|
| EECS 498-007 / 598-005 Assignment #2-1 (0) | 2021.01.16 |
| EECS 498-007 / 598-005 Lecture 4 : Optimization (0) | 2021.01.11 |
| EECS 498-007 / 598-005 Lecture 3 : Linear Classifier (2) | 2021.01.07 |
| EECS 498-007 / 598-005 Assignment #1 (0) | 2020.12.31 |

